
数据邪修大法好:仅用文本数据就能预训练多模态大模型
数据邪修大法好:仅用文本数据就能预训练多模态大模型没有图片,也能预训练多模态大模型?在多模态大模型(MLLM)的研发中,行业内长期遵循着一个昂贵的共识:没有图文对(Image-Text Pairs),就没有多模态能力。
来自主题: AI技术研报
8950 点击 2026-03-03 14:25
 搜索
搜索
没有图片,也能预训练多模态大模型?在多模态大模型(MLLM)的研发中,行业内长期遵循着一个昂贵的共识:没有图文对(Image-Text Pairs),就没有多模态能力。
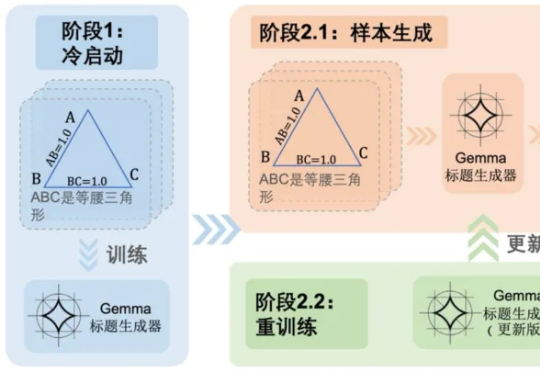
随着多模态大语言模型(MLLMs)在视觉问答、图像描述等任务中的广泛应用,其推理能力尤其是数学几何问题的解决能力,逐渐成为研究热点。 然而,现有方法大多依赖模板生成图像 - 文本对,泛化能力有限,且视

在当今的多模态大模型的发展中,模型的性能和训练数据的质量关系十分紧密,可以说是 “数据赋予了模型的绝大多数能力”。